下载地址:https://www.postgresql.org/
yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
yum install epel-release.noarch -y
yum install libzstd.x86_64 -y
yum install -y postgresql15-server
yum install -y postgresql15-contrib # 辅助工具包
sudo /usr/pgsql-15/bin/postgresql-15-setup initdb # 数据库初始化
sudo systemctl enable postgresql-15 --now
sudo systemctl status postgresql-15
firewall-cmd --permanent --add-port=5432/tcp # 添加防火墙配置
echo PostGreSQL|passwd --stdin postgres # 将用户postgres改在PostGreSQL
# 登录上数据库上
[root@mysql ~]# su - postgres
-bash-4.2$ psql # sqlplus的本地身份认证登录
psql (15.2)
输入 "help" 来获取帮助信息.
postgres=# \l # 查看数据库的信息
postgres=# \q # 退出本次登录
# 1.安装依赖包
yum install gcc-c -y
yum install readline-devel -y
yum install zlib-devel -y
yum install gcc -y
# 2.下载安装包
wget https://ftp.postgresql.org/pub/source/v15.2/postgresql-15.2.tar.bz2
[root@pg01 ~]# bzip2 -d postgresql-15.2.tar.bz2 ;tar -xvf postgresql-15.2.tar
[root@pg01 ~]# cd postgresql-15.2
[root@pg01 postgresql-15.2]# ./configure --prefix=/usr/local/gp15 # 编译测试
[root@pg01 postgresql-15.2]# make -j 4;make install -j 4 # 4CPU4线程编译安装
[root@pg01 local]# ln -sf /usr/local/gp15 /usr/local/gpsql # 创建一个软件连接
# 3.创建用户
useradd -u 5001 postgres
echo "123456"|passwd --stdin postgres
# 4.添加环境变量
[postgres@pg01 ~]$ cat .bash_profile
# .bash_profile
export PATH=/usr/local/pgsql/bin:$PATH
export LD_LIBARARY_PATH=/usr/local/pgsql/lib:$LD_LIBARARY_PATH
export PGDATA=/home/postgres/pgdata
# 5.创建实例
initdb
# 6.启动数据库
pg_ctl start -D $PGDATA
pg_ctl -D /home/postgres/pgdata -l logfile start
# 7.登录数据库
[postgres@pg01 ~]$ psql -d postgres -p 5432
postgres=# \l # 查看数据库的信息
# 8.关闭数据库
pg_ctl stop -D $PGDATA [-m smart|fast|immediate]
smart # 所有连接终止后关闭数据库,等侍所有的数据终止连接。
fast # 快速关闭数据库,回滚未提交的数据
immediate # 未提交的数据未回滚。下次启动恢复数据库最后的状态。
# 9.配置环境别名
cat <<END>> /home/postgres/.bashrc
alias pgst='pg_ctl start -D \$PGDATA'
alias pgsp='pg_ctl stop -D \$PGDATA -m immediate'
alias pglg='psql -d postgres -p 5432'
END
postgres # 这个是系统数据库
template0 # 简化的模板库
template1 # 在创建其它数据库时,以这个数据库为模板进行克隆
# 1.登录参数
pssql -U -W -h -p -d
-U 数据库的用户名
-W 数据库的密码
-h 数据库的IP地址
-p 数据库的访问端口
-d 需要访问数据库的名称(默认postgres)
# 2.修改数据库的管理员密码
[postgres@pg01 ~]$ psql -d postgres -p 5432
postgres=# alter user postgres with password '123456';
ALTER ROLE
# 3.禁止数据本地用户登录
sed -i 's/host all all trust/local all all md5/' \
/home/postgres/pgdata/pg_hba.conf
# 4.添加远程登录访问
# 配置远程登录用户采用密码验证验证的方式登录
echo "host all all 0/0 md5" >>/home/postgres/pgdata/pg_hba.conf
# 远程访问的端口与监听配置
sed -i "s/#port = 5432/port = 5432/" /home/postgres/pgdata/postgresql.conf # 打开网络端口访问
sed -i "s/#listen_addresses = 'localhost'/listen_addresses = '*'/" \
/home/postgres/pgdata/postgresql.conf # 打开网络监听
# 5.创建登录测试数据库与用户
create user zz with password '123456';
create database testdb with encoding='utf8' owner=zz;
grant all privileges on database testdb to zz;
# 6.登录测试
psql -U zz -h 127.0.0.1 -p5432 -d testdb -W'123456'
pgAdmin4 下载地址:https://www.pgadmin.org/
Navicat 16 下载地址:https://www.navicat.com.cn/
# 登录数据库
\? 或 \? # 获取帮助
\help ALTER SCHEMA # 获取修改schema的帮助
# 查看数据库信息
\l
# 切换数据库
postgres=# \c testdb; # 切换到testdb数据库
# 查看数据库下所创建的表
testdb=# \d
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | t1 | table | postgres
# 查看表的结构
testdb=# \d t2 # 查看t2表的结构
testdb=# \d+ t2 # 查看t2表的结构,里面会带一些相关注释信息
# 查看数据库下的所有对象
testdb=# \d *
# 查看数据库下的表中以t开头的对象
testdb=# \d t*
# 查看数据库下所创建的表
testdb=# \dt
# 查看数据库下所创建的索引
testdb=# \di
# 查看数据库下所创建的序列
testdb=# \ds
# 查看数据库下所创建的视图
testdb=# \dv
# 查看数据库下所创建的函数
testdb=# \df
# 查看数据库下所创建的schema
testdb=# \dn
# 查看数据库下所创建的表空间相关
testdb=# \db
# 查看数据库下所创建的所有角色
testdb=# \du & \dg # 显示用户与组的信息
# 查看数据库下所创建的用户权限
testdb=# \dp
# 查看数据库下相关命令所执行的时间
testdb=# \timing
# 查看数据库字符集 \encoding
# 修改字符集到GBK \encoding GBK
# 修改字符集到UTF8 \encoding UTF8
格式化输出\pest
\pset border0 # 无边框
\pset border1 # 内边框 - 默认
\pset border2 # 内外边框
\pset format unaligned # 内外边框
\pset fieldsep '\t' # 指定分割符
# sql输出的内容重定到指定操作系统目录文件中
\o sql.txt
select * from t1;
行列转换
\x
select * from pg_stat_activity;
执行外部的sql
\i aa.sql
编辑sql语句
# 编辑sql \e aa.sql # 编辑aa.sql文件 # 编辑函数 \ef # 编辑视图 \ev
echo输出
\echo ---------------- select * from t1; \echo ----------------
pg_ctl help # 查看帮助
-D 指定数据库配置文件系统的位置,可以在环境变量中指定 -s 只打印错误或警告信息不打印正确信息 -m 指定关机模式,smart、fast、immdiate -o 指定要直接传递给postgres命令的选项。-o可以多次指定,所有给定的选项都被传递 -c 尝试允许服务崩溃产生核心的core文件 -l 将服务器日志输出附加到文件名。 -p 指定postgres可执行文件的位置 -t 指定等待操作完成时等待的最大秒数(参见选项-w) -V 查看版本 -w 等待操作完成。 -W 不等待操作完成。
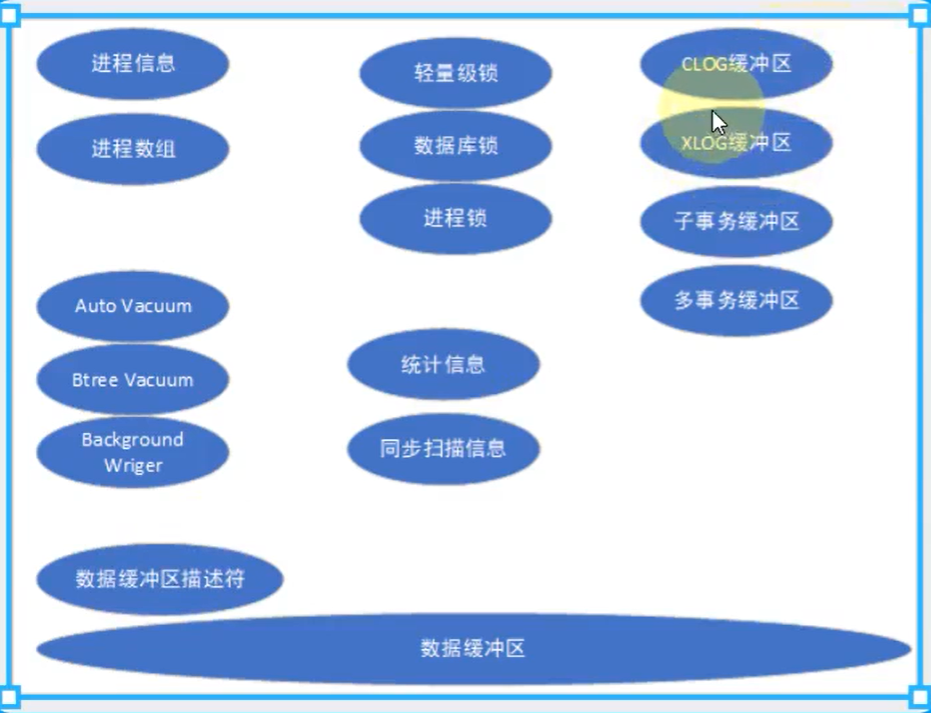
PG启动后会生成一块共享内存,作用是用作数据库的缓冲区,以便提高读写性能
暂存一些不需要全局存储的数据
临时缓冲区 # 使用临时表的本地缓存区 work_mem # 使用于内部排序操作,和hash表临时的产生的缓存区 maintenance_work_mem # 维护性的操作,比方法加索引等操作
注意:这里的database cluster指的是数据库簇表
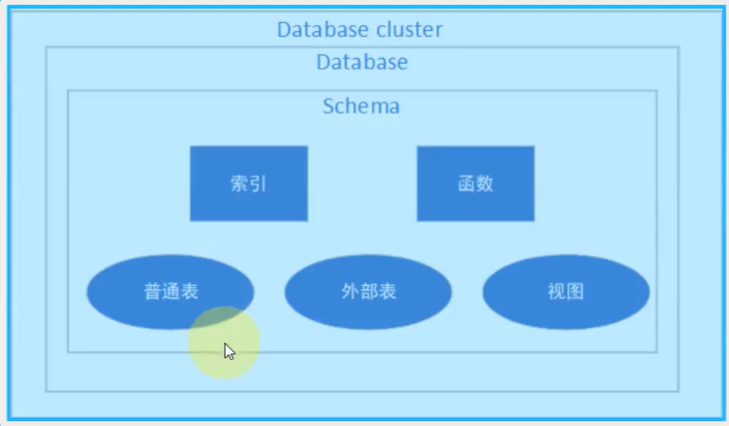
进程拓扑图
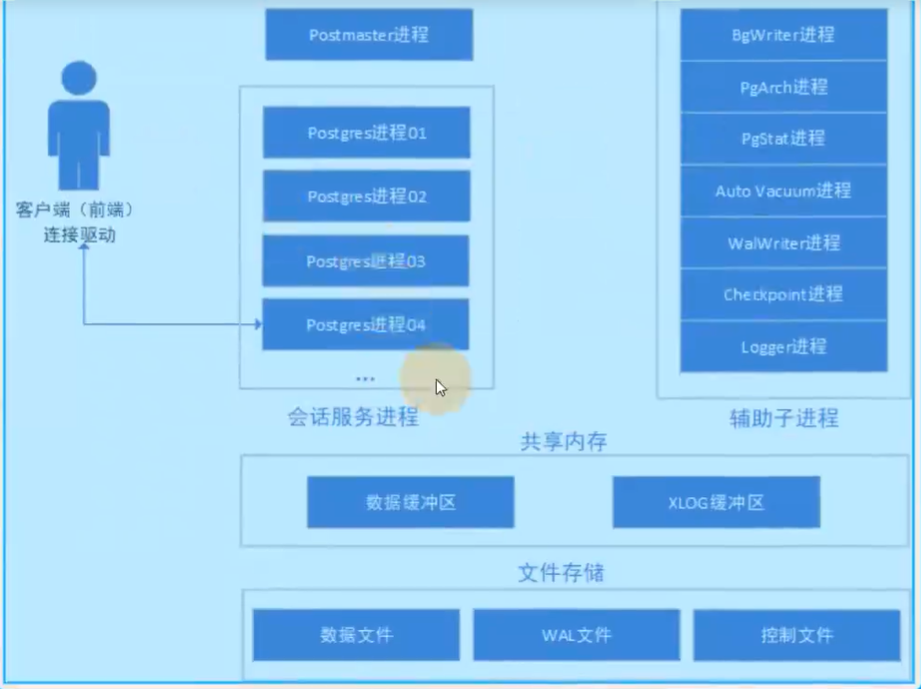
# 1.postgres 主进程 当PG数据库启动时,首先会启动Postmaster主进程,这个进程是PG数据库的总控制进程,负责启动和关闭数据库实例。 Postmaster进程是一个指向postgres命令的链接,当用户和PG数据库建立连接时,要先与Postmaster进程建立,此时客户端进程会发送身份验证消息进行身份验证,验证通过,postmaster主进程会产生一个会话服务进程 为这个用户连接服务 # 查看用户进程连接 select pid,usename,client_addr,client_port from pg_stat_activity; # 2.Logger 系统日志进程 通过postmaster进程,所有服务器进程及其它辅助进程收集所有的输出,写入到日志文件中。可以选择开启与不开启,配置信息在 postgresql.conf文件中。 # logging_collector = off 控制日志收集的开与关。 # log_destination 日志存放的方法,包括stderr、cslog、jsonlog和syslog。 # log_directory 该参数设置创建的日志文件的目录。 # log_filename 定义日志的文件名称。 # log_file_mode 该参数设置创建的日志文件的权限。 # log_rotation_age 单个文件存放日志的时间,如果时间超过则重新创建一个文件。 # log_rotation_size 单个文件大小,如果超过则重新创建一个。 # log_truncate_on_rotation 日志截断(覆盖),而不是追加任何现有的同名日志文件。 # syslog_facility 当syslog启用时,这个参数决定要使用syslog“工具”。 # syslog_ident 当ysslog启用时,此参数确定确定用于在syslog日志中识别PGSQL消息程序名。 # syslog_sequence_numbers 当日志记录到syslog且些选项默认开启,则每条消息针以递增的序列号作为前缀。 # syslog_split_messages 当日志记录到syslog启动时,此参数确定如何将消息传递到syslog. # event_source 当日志记录到syslog启动时,此参数用于标识日志中的PGSQL消息程序名称. # 3. BgWriter (预写式日志)进程 作用:定期把脏数据从内存缓存中区刷到磁盘中,减少查询时的阻塞。PG在定期作查检时需要把所有的脏页写出到磁 盘,通过BgWriter预先写出一些脏页,可以减少设置检查点(CheckPoint),使系统的IO负载趋向平稳。 参数:bgwriter_delay 进程连续两次flush数据之间的时间的间隔 bgwriter_lru_maxpages 控制backgroud writer进程每次写的最多数据量,默认200ms bgwriter_lru_mulitplier 表示每次往磁盘写数据块的数量,bgwriter的最大数据量计数方式。 计算公式: 1000/bgwriter_delay*bgwriter_lru_maxpages*8k=最大数据量 bgwriter_flush_after 数据页大小达到bgwriter_flush_after时触发bgwriter # 4.Walwirter(预写式日志写)进程 与oracle 中的redo日志相似,把修改的数据先记录到日志中。 参数:wal_level 决定多少信息被写入WAL。replica|Minaml|logical # 只读查询日志在有备库时用|最小化日志|解码日志 fsync 服务器将尝试通过发出fsync()系统调用或各种等效方法来确保更新被物理地写入磁盘。 synchronous_commit 数据库服务器向客户端返回"成功"指示之前必须完成WAL处理。 wal_sync_method 强制WAL更新到磁盘的方法,如果fsync是关闭的,那么这个设置是不相关的,因为WAL处理。 full_page_writes当该参数为开启时,在检查点对每个磁盘页进行第一次修改时,PGSQL服务器会将该磁盘页的全部内容写入WAL。 Wal_log_hints **** # 5.PgArch 归档进程 archive_mode: 将WAL日志进行归档,操作有三个 off | always |on # 6.AutoVacuum自动清理进程 清理历史数据 # 7.PgStat 统计数据收集进程 数据库的统计信息 # 8.CheckPoint检查点进程
[postgres@pg01 pgdata]$ tree ./ |grep conf$ ├── postgresql.auto.conf # auto_system配置参数的文件 9.4late ├── postgresql.conf # 数据主配置文件 ├── pg_ident.conf # 认证方式的映射文件 ├── pg_hba.conf # 登录认证文件 ├── base # 默认表空间目录 ├── global # 包含数据簇的子目录 ├── pg_commit_ts # 事务提交时间戳子目录 ├── pg_dynshmem # 共享内存子系统的目录 ├── pg_logical # 逻辑解码状态子目录 ├── pg_multixact # 用于共享行锁 ├── pg_notify ├── pg_** ├── pg_**
[postgres@pg01 pgsql]$ pwd /usr/local/pgsql [postgres@pg01 pgsql]$ ls bin include lib share
psql postgres=# create tablespace tab1 location '/home/postgres/'; [postgres@pg01 ~]$ ll drwx------ 2 postgres postgres 6 Feb 15 23:07 PG_15_202209061 # PG_15_202209061 # 15是一个数据的版本,202209061catalog的一个版本
SQL(Structured Query Language )结构化查询语言
DQL 数据查询操作 select DML 插入、删除、更新三种操作 DDL 定义数据库的逻辑结构,包括定义数据库,基本表,视图和索引 create alter drop truncate
create database testdb; # 创建一个testdb数据库。
\c testdb # 切换到testdb数据库上。
# 创建一个表
create table t1 (id int primary key,name varchar(20));
# 插入数据
insert into t1 values('11','zz');
insert into t1(id) values('12');
insert into t1 values('8','12'),
('1','11'),
('2','12'),
('3','13');
# t2表插入三条数据
insert into t2 values
('11','11'),
('22','12'),
('33','13');
# 将t2表中的数据插入到t1中
insert into t1(id,name) select id,name from t2;更新表中的某个值 update t1 set name='z1',id=100 where name='zz'; 某个字段下乘1.1 update t1 set id=id*1.1; returning * # 返回修改的值
# 删除某个表的某个字符操作 delete from t1 where id = 10; # 删除某个表的所有内容 delete from t1; 或truncate table t1;
# 简单查询 select 字段 as 别名1,字段 as 别名2 from 表名 t1 where t1,字段1='values'; # 限定查询 select * from t2 where id=10; select * from t2 limit 1; # 只显示一行 select * fom t1 offset 2; # 跳过5行查询 # order by 排序 select * from t3 order by id; # 升序 select * from t3 order by id desc; # 降序 select * from t3 order by id,name desc; # 两个字段排序,先按照id,如果id值相等再按name来排。 # 模糊查询 select * from t2 where like '%zz'; # 表示一个或多个字符 select * from t2 where like '_z'; # 表示一个字符 # select 插入查询 testdb=# create table t3(id int primary key,name varchar(20)); testdb=# insert into t3 select * from t2;
# 分组查询 聚合函数 count、avg、sum、max、min 数据存在重复值,如按性别、地区等,需要按照重复字段进行分组,统计相关的信息(group by;having) create table student(id int primary key,name varchar(20),age int,class_no varchar(10)); insert into student values (1,'张三','18','2'); insert into student values (2,'李四','19','1'); insert into student values (3,'王五','20','2'); insert into student values (4,'赵六','18','1'); insert into student values (5,'马七','19','2'); insert into student values (6,'戓八','20','1'); insert into student values (7,'汪二','18','2'); # 求每个班级有多少人,查询的字段中,只有包含分组的字段与聚合函数。 select class_no,count(*) from student group by class_no; # 先按照年龄然后按照班级分组,然后统计每个年龄段,在那个班,班里面的人数 select class_no,age,count(*) from student group by age,class_no order by class_no; # 对分组之后的数据筛选haveing select class_no,age,count(*) from student group by age,class_no having count(*) >1; select class_no,age,count(*) from student group by age,class_no having age >19;
确认查询的表、确认查询的字段、确认关联字段
create table ta1 (id int,name varchar(20));
insert into ta1 values(1,'a');
insert into ta1 values(2,'b');
insert into ta1 values(3,'c');
create table ta2 (id int,class_nu varchar(20));
insert into ta2 values(1,'语言');
insert into ta2 values(2,'数学');
insert into ta2 values(3,'英文');
insert into ta2 values(4,'语言');
insert into ta2 values(5,'数学');
insert into ta2 values(6,'英文');
# 拿到两个表的集合
select * from ta1 cross join ta2;
# 按照t2与t2表的id字段关联操作
select t1.id,t1.name,t2.class_nu from ta1 as t1,ta2 as t2;
# 举例
T1 {[inner]|{left|right|full}[outer]} join T2 on boolean_expression
T1 {[inner]|{left|right|full}[outer]} join T2 using (join column list)
T1 {[inner]|{left|right|full}[outer]} join T2
# 内连接以下三种写等价
select ta1.id,ta2.class_nu from ta1 inner join ta2 on ta1.id = ta2.id;
select * from ta1 inner join ta2 using (id);
select * from ta1 natural join ta2 ;
# 左右连接
select * from ta1 right join ta2 using (id);
# full连接
select * from ta1 full join ta2 using (id);# where 前 # where 后 in 表示在其中 exists 表示存在 <>!= 表示大于小于或等于与不等于 any 任意一个值,比方大于任意值或小于任意值 all 所有值
使用场景,两个或多个查询的结果可以使用集合操作,表之间必须有相同的字段
union query1 union [all] query2 有效地将query2的结果附加到query1 的结果,尽管不能保证这是初阶的返回行的顺序。此外,它从结果中消除重复行,与distinct方法相同,除非使用union all interspect 取两个查询中相同的值返回,取交集。 except 取两个查询中差集。
integer --int整形 smallint --int2 char varying(n) --varchar(n) numeric(m,n) --decimal(m,n)
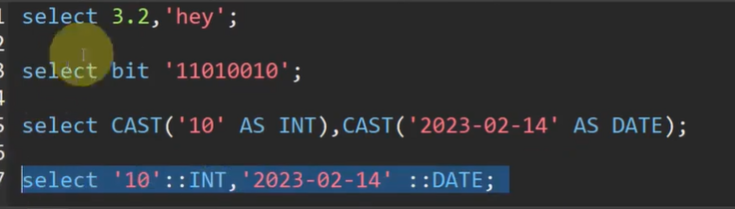
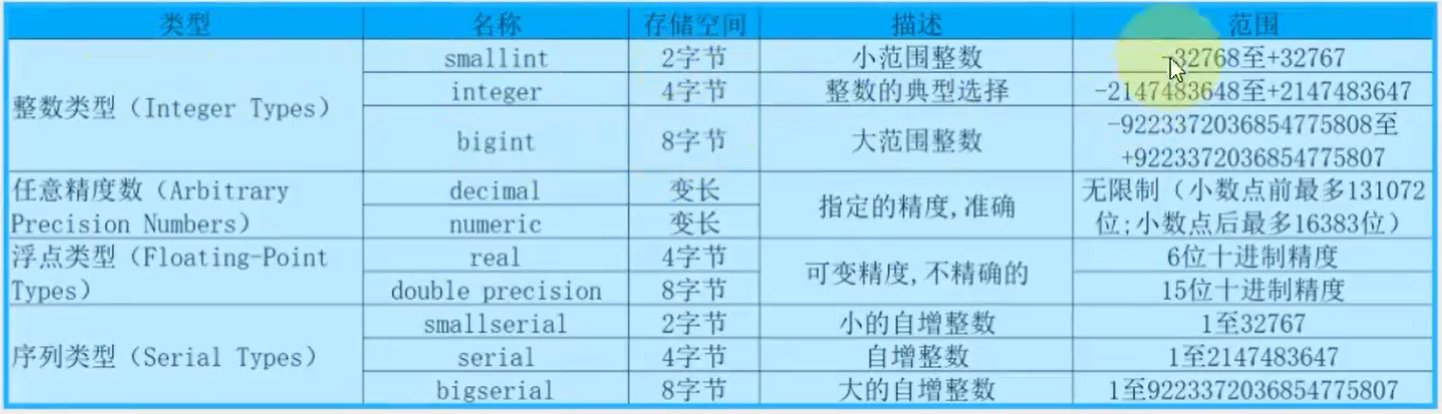
 泡杯长岛冰茶
12464
泡杯长岛冰茶
8904
泡杯长岛冰茶
12464
泡杯长岛冰茶
8904
 云贝教育
6805
云贝教育
6805
 AskGuo
6372
AskGuo
6372
 1菩提行者1
5665
云贝教育
5610
1菩提行者1
5665
云贝教育
5610

 19941464235
19941464235 junle.chen@yunbee.net
junle.chen@yunbee.net




点击加载更多